Clustering 101
Through clustering, companies can transform relatively cheap, commercial, off-the-shelf hardware into a powerful, reliable and expandable collection of computers that can be easily maintained and managed. But what exactly is clustering and how does it work? You're about to find out.
by Hinne Hettema
7/17/2001 -- High availability" is a key term in most electronic business today. In the Internet world, customers may (and will) visit your electronic storefront at any time of the day. They expect the shop to be open, an attendant available to take orders, and delivery to be on its way as soon as they hit the Send button on the checkout screen.
In many e-business environments, 30 minutes total downtime a year is close to unacceptable. It is now quite common to strive for 99.99 percent availability of computing services, which amounts to downtime measured in hours per year.
The problem is not limited to Internet ventures alone. The client/server environment we have in most businesses today is a distributed computing environment. Distributed computing environments are characterised by their dependency on servers for their proper functioning -- failure of a single server can render the whole environment unusable.
Apart from the need for high availability, performance and scalability are also becoming more important. Business, especially e-business, is a large and growing consumer of computing power. These systems need to be easily scalable -- if more users come online, the system must have the capacity to grow with the business.
Computer clusters offer all of the features above and more, at a relatively low cost. Through clustering, companies can transform relatively cheap, commercial, off-the-shelf hardware into a high availability, high performance and expandable solution that can be easily maintained and managed. Clusters will no doubt become more and more ubiquitous in the not too distant future; therefore, the time to start learning about them is now. Following is a guide to what clustering is, its most common configurations, and tips for networking and managing these configurations.
Defining Clusters
On the theoretical level, a cluster is quite simple: It is a collection of standard, off-the-shelf hardware, which is linked together in a network and runs specific software services. This configuration allows this collection of computers to work together as one more powerful computer.
There are generally two types of computer clusters: high performance and high availability. In the high availability scenario, only part of the cluster is used to do the work, and the remainder is left to idle until such time as one or more components fail. If that should happen, the other jumps in and takes over the tasks performed by the failed components, therefore providing uninterrupted service. In the high performance scenario, all components of this more powerful computer are being used all of the time.
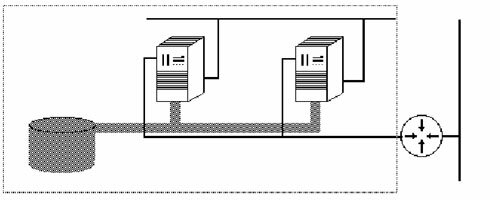
The figure below sketches a computer cluster. This particular cluster has a private and a public network, as well as external, shared storage.
| Origins of Clustering |
|
The history of 'high performance' computer clusters goes all the way back to the days of the "big iron" supercomputers. Supercomputers, such as the Cray Y-MP had multiple (vector) processors, which could share the often-heavy computational load of especially scientific applications. Such sharing required specific modifications to the operating systems, specialized compilers, and more often than not, extensive changes to the code of the program. Parallelism, as it was called then, was not cheap.
With the advent of the personal computer, clustering became a viable alternative to supercomputing for achieving parallelism. Clustering is scalable, "single points of failure" can be eliminated very effectively and, above all, it is a cheap solution to achieve high performance.
Also, in some circles (see www.beowulf.com) clustering smaller PCs was a way to deal with the (sometimes frustrating) task of engaging the vendors of supercomputers with technical issues. A beowulf is a cluster of computers that communicate over a separate network dedicated to cluster traffic, runs on commercial off the shelf hardware in which nodes fully trust each other. All this makes the cluster appear as a single high performance computer to the end user.
|
|
|
|
Individual computers in clusters are referred to as a node. The nodes can share resources as well as provide failover scalability.
As stated above, the aim of a high availability cluster is fairly simple: When one node in the cluster fails, another one takes its place. So even if one node fails, the cluster as a whole is always available. This feature is generally referred to as the failover capacity of a cluster.
The idea of high performance cluster is equally simple: A large computational load is shared among a collection of small resources, none of which would be able to process the load on its own.
In planning a clustering solution, resource dependency planning and a failover strategy are key, as is a serious consideration of networking issues.
Tip: Clustering is mostly used in the business environment because of availability. Your choice of hardware must reflect this. When you create an enterprise class cluster, make sure the hardware is of a high quality: i.e., hot-swappable, easily available and interchangeable. Also, it is probably a good idea to use fault-tolerant hardware as well -- servers with redundant power supplies, multiple network cards (even beyond the needs of public and private networks) and hardware RAID (Redundant Arrays of Inexpensive Disks).
Clustering Architecture
In general, the architectural features that turn a loosely connected collection of computers into a cluster fall into three categories:
- Resource Models
- Failover Models
- The Shared Bus
1. Resource Models
CPUs are not the only resources used in computing. The other two very important ones are memory and disks. Cluster nodes may share some of these resources between the nodes, and they may do this in different ways.
With the shared resource model, the nodes share a computing resource, most commonly a disk resource. That is, multiple cluster nodes have access to the same disk. Unfortunately, when you have two or more nodes that all want to write different data to the same place in a file, the integrity of the data can be compromised. Therefore, setting up this model correctly can get highly complicated.
Enter the shared nothing model. In this, the simplest (and most common) architecture, the nodes share no resources, thus the models name. In the shared nothing model (such as, for instance, Microsoft's Wolfpack) each node owns and manages its own resources. This model removes the complexity (and overhead) of locking the resource when it is in use by one node to preserve data integrity. The figure below sketches a cluster in a shared nothing configuration. Note that only one node has access to the disk.
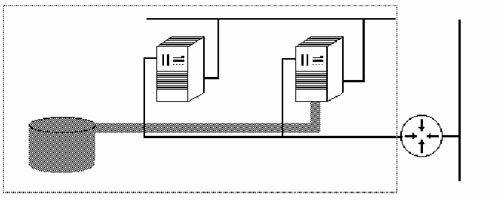
TIP: In most business computing environments, you'll only encounter cluster solutions when high availability is an issue. This is a lucky circumstance, since a high availability cluster works very well in the shared nothing model. The shared nothing model is much easier to implement and manage than a shared resource model.
2. Failover Models
One way in which failover can be configured is as an active/standby model. In this model, one of the cluster nodes is in standby mode, effectively waiting for one of the other nodes to fail. The advantage of this model is that there is no significant performance degradation of the cluster when a node fails, since an identical node takes over the operations within a few seconds. The disadvantage is that this model requires one computer to sit idle for most of the time.
In the active/active model, all nodes participate in the cluster, but may be responsible for the provision of different services. As an example, one node could run a file server, while the second node runs as a Web server. If, for example, the node running the file server service fails, the second node, which already runs the Web server, could provide the failover for the file server so that the file server remains available even when its original node fails. The disadvantage of this model is that there is generally a performance degradation when a node fails.
| The Quorum Resource |
|
A loose collection of computers is turned into a cluster because the nodes that comprise the cluster keep watch on each other. In brief, there exists a special process that watches all the other processes.
Cluster nodes may use a special section of the network (the private network) to send heartbeats from the application to the monitoring process. The monitoring process can probe the service at several levels. In Microsoft Cluster Service for instance, there is a difference between "looks alive" and "is alive."
Of course, as soon as the monitoring process notices a service is no longer online, it will attempt to failback the service to another node in the cluster.
Imagine what happens when a cluster node starts up. It knows it should be part of a cluster, but it doesn't know how many other nodes are currently joined in the cluster. The node starts up and looks for the cluster. If it sees the cluster on the network, it can join the cluster. But what to do if the starting node can't find the cluster?
This is where the quorum resource comes in. A quorum in political terms is normally the minimal number of members of a committee that has to be available for the committee to be officially in session.
The quorum resource is implemented in MSCS. It is owned by one node only (shared nothing model). If a cluster node is booting and if it owns the quorum resource, it establishes the cluster. If it doesn't, the node attempts to join an existing cluster. If it can't find the cluster, the node fails.
|
|
|
|
Not all applications can be run on a cluster effectively. An application needs to be "cluster aware" in order to utilize the benefits of the clustering software. This means it must be able to be stopped and restarted on another node and then pick up where it left off! This is obviously quite a big task, and not all applications have this availability or have even the ability to have it added.
3. The Shared Bus Model
Often, nodes in the cluster share a common hardware disk resource. This means that all nodes will be on a shared bus (often SCSI or fibre). If all nodes of the cluster are on a shared SCSI bus, this means that the configuration of the SCSI bus becomes crucial to the configuration of the cluster.
In particular, termination of the SCSI bus could become an issue. A SCSI bus needs to be terminated in order to function properly. In older SCSI hardware, this meant you had to use an external terminator on the bus. In modern SCSI hardware, termination is often internal. While this removes the need to have an external terminator on the bus, in computer clusters internal termination is not a good idea. If one or more nodes share the SCSI bus and one of the nodes fails, the whole bus could become unavailable. This means that all the devices connected to the bus become unavailable as well.
Tip: A so-called Y cable solves this problem.
Tip: Watch out for the SCSI ID of the controller as well. Most controllers are configured to use an ID of 7. As soon as you get multiple nodes onto the same SCSI bus, you use multiple controllers and have to change the ID on at least one of them.
Planning and Management
While the cluster can be managed as an individual entity, each node can still be managed individually. More specifically, and particularly in the shared nothing model, each service can be managed individually.
In planning services to run on a cluster, you have to keep track of resource dependencies. A resource such as a DNS name for the cluster is dependent on the existence of an IP address for the cluster as a whole. In turn, a Web server is also dependent on the existence of an IP address (and in most cases you'll want a DNS resource record somewhere as well). To follow on from there, almost everything you'll do on the cluster will require an IP address, disk space and computing resources to be available on the cluster.
Another issue to consider is where you want the application to run preferentially and where you want it to failover should the original node fails. The failover node should be powerful enough to deal with both the application it may already have been running, as well as the one that is assigned to it in the case of node failover.
The last issue to consider is failback. In failback, the service is moved back to the original node after the cluster detects that the original node has rejoined the cluster. Again, it is up to you to decide if you want this to happen. Some administrators prefer no failback, because the failover of a node may indicate a hardware problem with one of the nodes. Rather than have the cluster failover, failback, and failover again (and take a performance hit on each occurrence), they prefer to check out the node in some more detail first. Modern server management software normally monitors the hardware and allows for a maintenance engineer to be e-mailed or paged when something amiss is detected.
Networking Guidelines
There are a number of issues to be aware of when networking a cluster. This section will look at these. (NOTE: the rest of this article will assume that you are working with a Windows 2000 Advanced Server cluster).
First of all, most clusters will have nodes with two network interface cards each. This is because two network interface cards provide redundancy against a single failure in a card. Also, it is sometimes a good idea to separate the network used by clients of the cluster (the public network in Microsoft parlance) from the network used for cluster related communication between nodes (the private network).
Both public and private networks need to be designed with care. Following are tips for each.
Private Networks
The goal on a private network is to create a reliable, fast and low-maintenance connection between cluster nodes. You'll want to observe the following guidelines when designing a private network:
- Private IP addressing, as specified in RFC 1918, is preferred. If by mistake these network addresses were to make it onto a public network, they would not be routed.
- For connectivity, use a crossover cable when you have only two nodes. With more, provide a hub or a switch. (Although in these cases, you may wish to consider doubling the private network, since now the hub or the switch has become the single point of failure.)
- Do not use a router in the private network. Routers have a higher latency than switches, and packets can spend too much time being routed from one subnet to another.
- Put all nodes on the same subnet.
On a private network, running over TCP/IP is a relatively cheap solution to internode communication. However, It does not allow for shared memory, can be relatively slow (100 megabit-per-second over UTP cable), and should be switched at the most, which limits the number of nodes to those on the same IP subnet.
| Test Your Clustering Knowledge |
|
In the Windows 2000 MCSE track, Microsoft offers an exam on clustering (70-223). See the Microsoft Web site for more information, or read CertCities.com's review of this exam.
|
|
|
|
Current research in the area uses much more outlandish solutions, which are faster, sometimes allow for memory sharing and have less node limitations than IP, including Myrinet (a gigabit-per-second network architecture derived from the communication technology implemented in supercomputers) and the Scalable Coherent Interface (a recent IEEE standard for cluster interconnects, which allows for cluster-wide memory sharing).
Public Networks
When working with a public network, you'll need to make some decisions before you start:
- Do you want the public network to provide backup for the private network? This is a good idea if the private network uses a hub or a switch, which provides a single point of failure.
- Consider the configuration of the router connected to the public network. This router will handle traffic from both individual nodes and all cluster traffic. Since you only put a cluster in when you need high performance and high availability, the connection of the cluster to the outside world (i.e., the router) should be on a par with these requirements.
With a public network, you'll have to design for three types of IP addresses:
- The IP address for administrative access to the cluster.
- The IP address for each cluster node.
- The IP address for each service that clients can access.
It is generally advisable to separate all these IP addresses. The cluster IP address is for administrative access for you (the cluster administrator) only, as are the IP addresses for each node. You do not want these IP addresses to fail over, but rather stay put even if a node fails for administrative purposes.
The service IP addresses are the ones your clients will use to access resources on the cluster. The reason to have these separate is that this last category of IP addresses can be failed over. In fact, it should be failed over to provide the reliability that the cluster needs. You will configure the last addresses from within the cluster service itself.
For these IP addresses, there is another issue to consider related to the Address Resolution Protocol (ARP). At the logical link control (LLC, OSI layer 2) level, computers communicate using their MAC addresses. ARP takes care of the translation from the network (OSI layer 3) address to the MAC (OSI layer 2) address.
When a client requests a connection to a specific IP address, the client initiates this request by broadcasting an ARP request onto its local subnet. The computer that owns this IP address will respond with an acknowledgment, giving its MAC address. If an IP address is not on the same subnet as the client, the client will detect this (it knows the subnet mask) and ask for the IP address of the gateway (router interface) instead. The returned data are stored in the client's ARP cache for future reference.
Keep on Clustering
In this article, we have covered only the basics of clustering solutions. To create a working solution, it is important that you have a sound conceptual understanding of cluster architectures and networking. With this in mind, I have provided the following list of resources for getting more information. With these, you should be well on your way to understanding this growing technology area.
| Clustering Resources |
|
Books
- Windows 2000 Cluster Service Guidebook by David Libertone (Prentice Hall, 2000) -- An easy-to-read introduction to Microsoft's Cluster service on Windows 2000.
- Windows 2000 Server Resource Kit (Microsoft Press, 2000) -- Check out the chapters on distributed computing for advanced information. Don't forget the relevant chapters in the Planning and Deployment Guide.
- High Performance Cluster Computing, Architectures and Systems: Volume 1 edited by G. Pfister (Prentice Hall, 1999) -- An introduction to the theoretical concepts.
Web Sites
- Beowolf.org -- A clustering solution that can be implemented under Linux.
- Labmice.net Clustering page -- A good resource for Windows 2000 clustering information.
- http://www.microsoft.com/windows2000/library/
resources/reskit/dpg/chapt-18.asp -- Discusses planning issues of clustering in Windows 2000.
- http://www.microsoft.com/windows2000/library/
technologies/cluster/default.asp -- Contains an overview of the implementation of MSCS in Windows 2000.
|
|
|
Hinne Hettema works for a large computing outsourcing firm in Auckland, New Zealand, specialising in the area of Application Service Providers. He is Microsoft (MCSE NT4 and W2K), Citrix (CCA) and Cisco (CCNP) certified and has a PhD in computational chemistry and an MA in philosophy. He lives in a 1930s villa on the edge of the Manukau harbour with his wife, daughter and three cats, as well as numerous computers. He is also the editor of 'Quantum Chemistry: Classic Scientific Papers' (World Scientific, Singapore 2000). He can be reached at and likes to receive email.
More articles by Hinne Hettema:
|

 Feature Story
Feature Story